 Image showing detections in the last stage of the pipeline.
Image showing detections in the last stage of the pipeline.
Bib recognition is the task of identifying and reading the identification numbers that athletes wear during race events. Automating this task is valuable for sports photographers who often have to tag ten thousands of athletes for larger events. Initially the problem seems quite simple, but in many cases the numbers are partially occluded or heavily distorted, making a reliable solution quite difficult. This project served me as a practical example while learning to use tensorflow and over the time I developed quite a sophisticated multi stage pipeline to tackle the problem.
 Image showing example input picture where athlete ids (bibs) have to be detected.
Image showing example input picture where athlete ids (bibs) have to be detected.
The pipeline consisted of a bib extraction stage, where whole bibs were localized within the image, subsequently going through the number extraction stage, where the closer bounds of the number were detected and the surrounding logos were cropped away. The third stage then detected the single digits and a gaussian mixture model was used to detect duplicate and throw away erroneous detections based on bounding box position and shape. This was also the first project where I experimented with synthetic training data, achieving a large performance gain on the digit recognition stage.
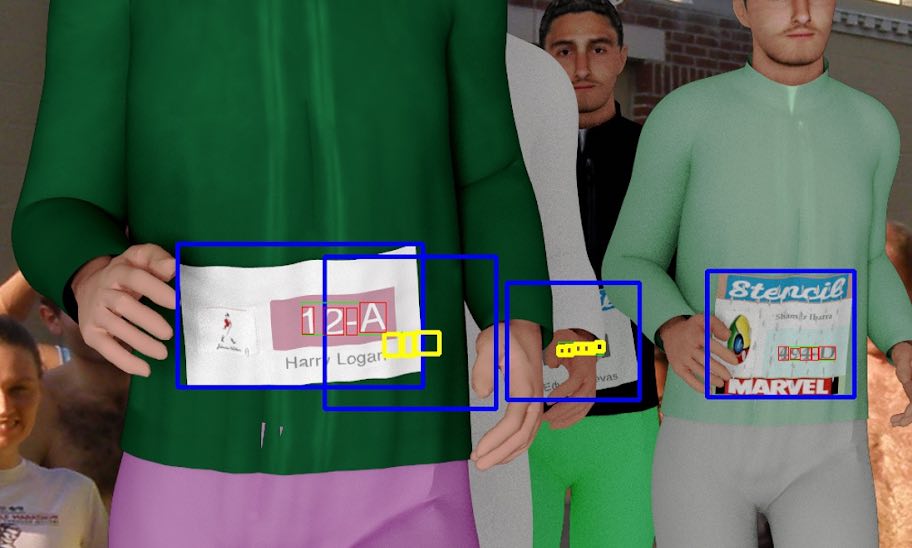 This image shows the automatically annotatable training images which were used for training some of the involved networks, including occluded labels (yellow).
This image shows the automatically annotatable training images which were used for training some of the involved networks, including occluded labels (yellow).